51. 다음의 릴레이션 R과 함수 종속을 고려해 보자. 이 릴레이션을 BCNF로 올바르게 분해한 것은? (다음 답항에서 밑줄은 후보키를 의미함.)
|
R(A, B, C)
후보키: (A, B) 함수종속: (A, B)→C C→B |
① R1(A, C), R2(A, B)
② R1(B, C), R2(B, A)
③ R1(C, B), R2(C, A)
④ R1(A, B, C), R2(C, B)
52. 수퍼타입 개체 A가 서브타입 개체 B와 C로 세분화 (specialization)된다고 하자. 다음의 벤다이어그램과 의미가 동일한 Extended E-R 다이어그램은? (단, 수퍼타입과 서브타입을 연결하는 중간 원 안의 표시 ‘d’는 disjoint를, ‘o’는 overlap을 표현 하고, 또한 수퍼타입 쪽의 단일선은 partial specialization을, 이중선은 total specialization을 표현 한다.)
 |
53. 다음 스케줄에 대한 설명으로 옳은 것은? (트랜잭션 연산 앞의 표기는 시간을 시:분:초로 표시한 것임)
|
01:00:01 T1 read(x)
01:00:02 T2 write(x) 01:00:03 T1 write(x) 01:00:04 T3 write(x) |
① 충돌 직렬가능과 뷰 직렬가능을 모두 만족하는 스케줄이다.
② 충돌 직렬가능은 만족하고 뷰 직렬가능은 만족 하지 않는 스케줄이다.
③ 충돌 직렬가능은 만족하지 않고 뷰 직렬가능은 만족하는 스케줄이다.
④ 충돌 직렬가능과 뷰 직렬가능을 모두 만족하지 않는 스케줄이다.
54. 인덱스 튜닝과 관련된 설명으로 가장 거리가 먼 것은?
① R.A가 S.B를 참조하는 외래키일 때, S.B에 대한 인덱스는 R에 대한 삽입 속도를 높여줄 수 있다.
② 동등(equality) 및 비동등(nonequality) 질의에는 해시 구조의 인덱스가 유용하다.
③ 단일 디스크 판독으로 테이블 전체를 읽을 수 있을 정도의 소형 테이블에 대한 인덱스는 성능 저하를 일으킬 수도 있다.
④ 인덱스 사용으로 인해 질의에서 절약되는 시간 보다 삽입이나 갱신에서 손해보는 시간이 더 크다면 인덱스를 사용하지 않는 것이 좋다.
55. 연관규칙 탐사와 Apriori 원리에 관련된 설명 중 잘못된 것은?
① 지지도란 해당 항목집합을 포함하는 트랜잭션의 비율을 말한다.
② 항목집합 {A,B}가 빈발하지 않다면 항목집합 {A,B,C}도 빈발하지 않다.
③ 항목집합 {A,B}의 지지도는 항목집합 {A,B,C}의 지지도 보다 크거나 같다.
④ 규칙 {A,B}→{C,D}의 신뢰도가 {A,B,C}→D의 신뢰도보다 크거나 같다.
56. 다음은 데이터베이스 시스템의 3-층 구조(3-tier architecture)에 대한 설명이다. ㉮와 ㉯에 들어갈 용어로 가장 적합한 것은?
|
3-층 구조는 2-층 구조(2-tier architecture)를 구성하는 클라이언트와 데이터베이스 서버 사이에 중간 단계를 하나 더 추가한 것이다. 중간 단계는 일반적으로 ( ㉮ )라 부르며 ( ㉯ ) 을 처리한다.
|
㉮ ㉯
① 응용 (프로그램) 서버 함수형 프로그램
② 응용 (프로그램) 서버 비즈니스 로직
③ 클라우드 (프로그램) 서버 함수형 프로그램
④ 클라우드 (프로그램) 서버 비즈니스 로직
57. 다음은 관계 데이터 모델에서의 주요 제약조건 네 가지를 나타낸다. 릴레이션에 대해 투플 삽입 연산이 발생한다면, 다음 중 어떤 제약조건들이 위배될 수 있는지 바르게 나열한 것은?
|
가. 도메인 제약조건(domain constraint)
나. 키 제약조건(key constraint) 다. 엔티티 무결성 제약조건(entity integrity constraint) 라. 참조 무결성 제약조건(referential integrity constraint) |
① 가, 나, 라
② 가, 다, 라
③ 나, 다, 라
④ 가, 나, 다, 라
58. 다음 중 SQL 뷰(view)에 대한 설명으로 적합하지 않은 것은? (2개 선택)
① 뷰에 대한 투플의 삽입은 시스템에 의해 거부될 수 있다.
② 원본과의 불일치 문제로 인해 뷰 생성 시 GROUP BY 절을 사용할 수 없다.
③ 집계(aggregation)에 의해 생성된 뷰의 경우 일반적으로 갱신을 허용하지 않는다.
④ 실체화된 뷰(materialized view)를 생성할 경우 에는 CREATE VIEW 구문을 사용하고, 그렇지 않은 뷰를 생성할 경우에는 CREATE TABLE을 사용한다.
59. 낙관적 동시성 제어(optimistic concurrency control) 에서 각 트랜잭션은 세 가지 단계로 실행되는데, 그 단계를 순서대로 바르게 나열한 것은?
① 읽기 단계(read phase) - 검증 단계(validation phase) - 쓰기 단계(write phase)
② 갱신 단계(update phase) - 검증 단계(validation phase) - 종료 단계(commit phase)
③ 갱신 단계(update phase) - 종료 단계(commit phase) - 검증 단계(validation phase)
④ 읽기 단계(read phase) - 쓰기 단계(write phase) - 검증 단계(validation phase)
60. 문서 d에서 단어 “감리사”의 TF(term frequency) 값이 3이라 하고, 문서집합 D에서 단어 “감리사”의 IDF(inverse document frequency) 값이 0.3010이라 하자. 그렇다면, 문서집합 D와 문서 d에서 단어 “감리사”의 TF-IDF 값을 바르게 계산한 것은?
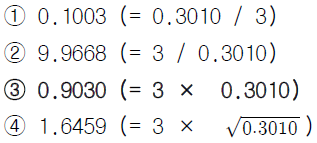
61. 다음은 데이터 마이닝 기법 중에서 무엇에 대한 설명인가?
|
연속성을 갖는 변수의 미래 값을 (다른 변수 값들을 활용하여) 예측하는 방법으로, 일반적으로 변수에 대해 선형 혹은 비선형 모델을 가정한다.
|
① 회귀분석(regression analysis)
② 연속변수분석(continuous variable analysis)
③ 상관관계분석(correlation analysis)
④ 다변량분석(multivariate analysis)
62. 규칙 기반 분류기(rule-based classifier)를 사용하여 다음의 훈련 집합으로부터 "(Marital Status = Single) → No"라는 규칙 r을 찾았다. 이 때, 이 규칙 r의 적용범위 Coverage(r)과 정확성 Accuracy(r)로 옳은 것은?
 |
63. 다음 표는 다차원 데이터 모델에서의 OLAP 연산들을 설명한 것이다. 표의 ㉮, ㉯에 들어갈 연산 들이 바르게 짝지어진 것은?
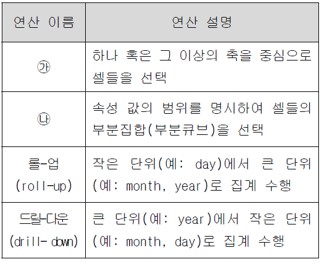 |
㉮ ㉯
① 다이싱(dicing) 슬라이싱(slicing)
② 슬라이싱 다이싱
③ 피벗팅(pivoting) 다이싱
④ 다이싱 피벗팅
64. 버클리 대학의 Eric Brewer 교수가 발표한 CAP 이론은 분산 컴퓨팅 환경의 세 가지 특징을 정의하고 있는데, NoSQL은 이중 한 두 가지 특징을 포기하는 대신 고성능, 확장성 등의 지원에 초점을 맞추고 있다. 여기서 CAP 이론의 세 가지 특징을 바르게 기술한 것은?
① C-Consistency, A-Atomicity, P-Persistency
② C-Concurrency, A-Atomicity, P-Partition Tolerance
③ C-Consistency, A-Availability, P-Partition Tolerance
④ C-Concurrency, A-Availability, P-Persistency
65. 다음은 고객(Customer)과 주문(Orders)에 관한 릴레이션이다. 밑줄 친 속성은 기본키이고, 점선 밑줄은 외래키이다. 2개의 릴레이션을 이용하여 고객의 아이디(custid), 이름(name)과 고객이 구매한 책 값(saleprice)의 총액을 구하고자 한다. 작성된 SQL문 중 틀린 것은?
|
(릴레이션)
Customer(custid, name) Orders(orderid, custid, bookname, saleprice) |
① SELECT custid, (SELECT name FROM Customer cs
WHERE cs.custid = od.custid)
AS name, SUM(saleprice)
FROM Orders od
GROUP BY od.custid;
② SELECT cs.custid, cs.name, s
FROM (SELECT custid, SUM(saleprice) s
FROM Orders GROUP BY custid) od,
Customer cs
WHERE cs.custid = od.custid;
③ SELECT cs.custid, cs.name, s
FROM Customer cs, Orders od
WHERE cs.custid = od.custid AND
(SELECT SUM(saleprice) s FROM Orders od);
④ SELECT cs.custid, cs.name, SUM(saleprice)
FROM Customer cs, Orders od
WHERE cs.custid = od.custid
GROUP BY cs.custid, cs.name;
66. 다음 그림은 트랜잭션들을 병행 수행시킨 후 로그의 기록이다. 데이터베이스 시스템 수행 중 시스템에 이상이 생겼다. 이상이 생긴 후 로그의 기록을 살펴보니 다음과 같았다. 로그는 데이터 베이스의 변경에 대한 기록으로 즉시 변경(immediate update) 방법을 사용한다. 이 상태에서 복구를 하고자 한다. 로그의 <T,DI,v1,v2>는 순서대로 <트랜잭션 이름, 데이터 항목, 변경전 값, 변경후 값>을 나타낸다. 트랜잭션들의 복구 후 데이터 값에 대한 내용 중 틀린 것은?
|
<start, T1>
<T1, D, 20, 30> <commit, T1> <checkpoint> <start, T2> <T2, C, 12, 13> <start, T4> <T4, B, 15, 16> <start, T3> <T3, D, 30, 31> <T4, A, 20, 21> <commit, T4> *system crash* |
① A: 21 ② B: 16
③ C: 12 ④ D: 31
67. 정보검색에 있어서 재현률(recall)을 다음의 정보 검색 결과표를 이용하여 기술하였을 때 올바른 것은?
|
(정보검색 결과표)
TP(True Positive): 검색된 결과 중 실제 정답인 정보의 수 FP(False Positive): 검색된 결과 중 실제 정답이 아닌 정보의 수 FN(False Negative): 검색되지 않은 정보 중 실제 정답인 정보의 수 TN(True Negative): 검색되지 않은 정보 중 실제 정답이 아닌 정보의 수 |
① TP/(TN+FP) ② TP/(TP+TN)
③ TP/(TP+FN) ④ TP/(FP+FN)
68. 릴레이션 'employee'와 'department'에서 다음 SQL 질의문의 수행결과는?
|
<질의문>
SELECT e.dno, d.dname, e.ename, e.score FROM employee e, department d WHERE e.dno = d.dno and (e.dno, score) IN (SELECT dno, max(score) FROM employee GROUP BY dno); |
 |
① { (100, 영업, Lee, 90), (200, 개발, Kim, 95), (300, 서비스, Hong, 65) }
② { (100, 영업, Lee, 90), (200, 개발, Kim, 95) }
③ { (100, 영업, Lee, 90) }
④ { (100, 영업, Hong, 80), (100, 영업, Lee, 90), (200, 개발, Kim, 90), (200, 개발, Kim, 95), (600, null, Hong, 65) }
69. 다음의 데이터베이스에서 ‘부양가족을 2명 이상 가진 사원의 사번(eno), 성명(ename), 부양가족 수를 검색’하는 질의를 SQL로 적절하게 표현한 것은? (단, 밑줄은 스키마에서 기본키를 의미한다.) (2개 선택)
|
employee(eno, ename, adddress, score, dno)
dependent(eno, dename, birthdate, relation) |
① SELECT eno, ename, count(*)
FROM employee e, dependent d
WHERE e.eno = d.eno and count(*) >= 2
GROUP BY d.eno;
② SELECT e.eno, e.ename, count(*)
FROM employee e, dependent d
WHERE EXISTS (SELECT * FROM dependent
GROUP BY eno HAVING count(*) >= 2)
GROUP BY e.eno, e.ename;
③ SELECT e.eno, e.ename, t.cnt
FROM employee e, (SELECT eno, count(*) as cnt
FROM dependent GROUP BY
eno HAVING count(*) >= 2) t
WHERE e.eno = t.eno;
④ SELECT e.eno, e.ename, count(*)
FROM employee e, dependent d
WHERE e.eno = d.eno
GROUP BY e.eno, e.ename
HAVING count(*) >= 2;
70. 관계 대수는 일반적으로 다섯 가지 기본 연산을 가지며, 이를 관계 대수 연산의 완전 집합(complete set)이라 부른다. 완전 집합의 다섯 가지 기본 연산들을 바르게 나타낸 것은? (단, π는 Π로 표현하기도 한다.)
① { σ, π, × , ∪, ∩ }
② { σ, π, ⋈, ∪, ÷ }
③ { σ, π, × , ∪, − }
④ { σ, π, ⋈, ∪, ∩ }
71. 다음은 회사 데이터베이스의 일부를 표현한 E-R 다이어그램이다. 밑줄 친 속성은 키 속성을 의미 한다. 이 E-R 다이어그램을 BCNF에 속하는 릴레이션으로 변환하는 과정을 기술한 설명으로 가장 적절한 것은?
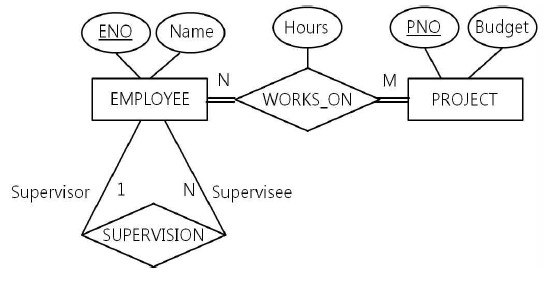 |
① EMPLOYEE(ENO, Name) 릴레이션에 Supervisee의 ENO 속성을 외래키로 추가한다.
② EMPLOYEE(ENO, Name) 릴레이션에 Supervisor의 ENO 속성을 외래키로 추가한다.
③ EMPLOYEE(ENO, Name) 릴레이션에 Hours 속성을 추가한다.
④ PROJECT(PNO, Budget) 릴레이션에 Hours 속성을 추가한다.
72. 트랜잭션 관리의 회복 기법에서 체크포인트(check point)를 사용한다고 가정하자. 다음과 같이 체크 포인트가 사용될 때, 시스템이 다운된 후 회복 관리자가 수행하는 연산으로 틀린 것은? (2개 선택)
|
체크포인트 c가 정상적으로 수행되고 체크 포인트 f가 수행될 때 시스템이 다운되었다. 트랜잭션 T1은 c 이전에 시작해서 c 이전에 완료되었고, T2는 c 이전에 시작해서 f 이전에 완료되었다. T3는 c 이전에 시작해서 f일 때 수행 중이었고 T4는 c 이후에 시작해서 f 이전에 완료되었다. T5는 c 이후에 시작해서 f일 때 수행 중이었다.
|
① Undo-list에 있는 모든 트랜잭션들에 대해 로그에 기록된 순서대로 Undo 연산을 수행한다.
② T1은 회복 작업에 관련될 필요가 없다.
③ T2는 c 이후에 일어난 변경 부분에 대해서만 Redo 연산을 수행한다.
④ T3는 c 이후에 일어난 변경 부분에 대해서만 Undo 연산을 수행한다.
73. SQL의 질의처리 성능을 개선하기 위해 튜닝할 때, 불필요한 소트(sort)가 발생하지 않도록 하는 것으로 거리가 먼 것은? (2개 선택)
① Union ALL을 Union으로 대체
② Distinct를 Exists 서브쿼리로 대체
③ Sort Aggregate를 Sort Unique로 대체
④ 데이터 존재 여부만을 확인할 경우 불필요한 Count 연산 제거
74. 다음의 릴레이션 A와 B에 대해 어떤 연산을 했을 때, 그 결과로 릴레이션 C가 얻어진다. 이 때 C가 얻어지도록 하는 어떤 연산은 무엇인가?
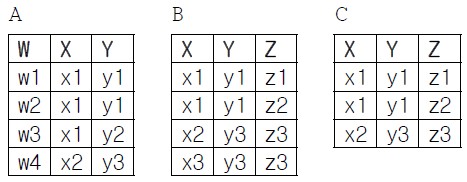 |
① A와 B의 왼쪽 외부조인(left outer join)
② A와 B의 오른쪽 외부조인(right outer join)
③ A에 대해 B의 세미조인(semijoin)
④ B에 대해 A의 세미조인(semijoin)
75. 어떤 릴레이션 R(A, B, C, D, E, F, G)에서 다음과 같은 함수 종속성이 존재한다고 가정하자. 이 때 릴레이션 R에서 후보키가 아닌 것은?
|
CE → A, A → ABCDEFG, BD → E
|
① CE ② A ③ BD ④ BCD
정답)
|
51
|
52
|
53
|
54
|
55
|
|
③
|
②
|
③
|
②
|
④
|
|
56
|
57
|
58
|
59
|
60
|
|
②
|
④
|
④
|
①
|
③
|
|
61
|
62
|
63
|
64
|
65
|
|
①
|
①
|
②
|
③
|
③
|
|
66
|
67
|
68
|
69
|
70
|
|
④
|
③
|
①
|
④
|
③
|
|
71
|
72
|
73
|
74
|
75
|
|
②
|
①,④
|
①,③
|
④
|
③
|
'정보시스템감리 기출문제 > 데이터베이스' 카테고리의 다른 글
| (제 14회) 데이터베이스 / (51)~(75) (1) | 2024.01.12 |
|---|---|
| (제 15회) 데이터베이스 / (51)~(75) (1) | 2024.01.11 |
| (제 17회) 데이터베이스 / (51)~(75) (1) | 2024.01.09 |
| (제 18회) 데이터베이스 / (51)~(75) (1) | 2024.01.08 |
| (제 19회) 데이터베이스 / (51)~(75) (1) | 2024.01.07 |