문제 5) 군집분석(Cluster Analysis)
답)
1. 개체집합 내 유사성 분석, 군집분석의 개요
가. 군집분석(Cluster Analysis)의 개념
|
개념도
|
정의
|
 |
|
|
|
나. 군집분석(Cluster Analysis) 의 특징
|
탐색적
|
주어진 자료의 사전정보 없이 의미 있는 자료구조 탐색
|
|
데이터
|
거리가 정의된 다양한 형태의 데이터에 적용 가능
|
|
유사도
|
물리적 거리가 가까운 항목들은 동일 집단으로 묶임
|
|
|
2. 군집분석(Cluster Analysis)의 거리 및 유사도 척도
가. 군집분석(Cluster Analysis)의 거리 척도
|
구분
|
측정
|
설명
|
|
유클라디안 거리
|
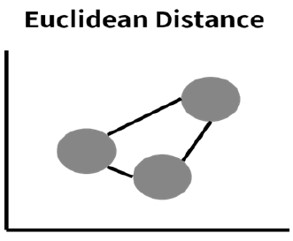 |
좌표상에서 데이터들 간의 직선거리를 의미 함함
 |
|
맨하튼 거리
|
 |
절대값을 합산하는 방식이며방식이며, 초록색은 유클리드 거리이며 나머지는 모두 맨하튼 거리임거리임
 |
|
마할라 노비스 거리
|
 |
변수의 분산과 상관성을 고려한 거리 측정 방법으로 변수 간의 상관관계가 있을때 유용함유용함
 |
|
||
나. 군집분석(Cluster Analysis)의 유사도 척도
|
구분
|
측정
|
설명
|
|
코사인유사도
|
 |
좌표상에서 데이터들 간의 Cosine값
 |
|
자카드유사도
|
 |
집합간의 교집합 크기를 이용해서 유사도를 측정하는 방법
 |
|
||
3. 군집분석(Cluster Analysis) 알고리즘
|
구분
|
설명
|
특징
|
|
K-means
|
|
|
|
DBSCAN
|
|
|
|
GMM
|
|
|
|
계층 클러스터링
|
|
|
|
||
공감과 댓글은 아이티신비에게 큰 힘이 됩니다.
블로그 글이 유용하다면 블로그를 구독해주세요.♥
'정보관리기술 > 데이터베이스' 카테고리의 다른 글
| 데이터 거버넌스(Data Governance) / ① (85) | 2024.02.29 |
|---|---|
| 텐서플로(TensorFlow) / ① (5) | 2024.02.29 |
| 데이터 시각화(Data Visualization) (79) | 2024.02.28 |
| 오피니언 마이닝(Opinion Mining) (0) | 2024.02.14 |
| 웹 크롤링(Web Crawling) (25) | 2024.02.13 |