51. 다음은 빅데이터 시스템의 NoSQL 데이터 모델 중 하나를 설명한다. 이 데이터 모델의 명칭으로 가장 올바른 것은?
|
① 문서 기반 데이터 모델(document based data model)
② 객체 지향 데이터 모델(object-oriented data model)
③ 구조 기반 데이터 모델(structure based data model)
④ 자바 기반 데이터 모델(Java based data model)
52. 다음에 주어진 관계 대수(relational algebra) 연산의 결과에서 결과 테이블의 카디널리티(cardinality)가 가장 큰 것과 가장 작은 것의 합으로 옳은 것은?

|
R÷(ΠB(S))
R⋈NS R⋈R.B<S.BS σB=10(R) |
① 6 ② 7
③ 8 ④ 11
53. 릴레이션 R과 S의 속성 A를 통한 이원 조인 (two-way join)의 구현 방법 중에서 릴레이션 R과 S가 조인 속성 A에 대해 오름차순으로 정렬되어 있을 경우에만 적용 가능한 방법은?
① 중첩 루프 ② 인덱스 검사
③ 해시 검사 ④ 정렬 합병
54. 낙관적 로킹(optimistic locking)과 비관적 로킹 (pessimistic locking)에 대한 설명 중 옳지 않은 것은?
① 일반적으로 인터넷은 비정형적이고 체계화되지 않은 곳이므로 사용자들이 트랜잭션 수행 중에 작업을 중단하는 등의 예상치 못한 행동을 하여 비관적 로킹을 사용하는 것이 더 효율적이다.
② 만약 트랜잭션이 복잡하거나 클라이언트의 속도가 느린 경우 낙관적 로킹을 사용하면 극적으로 생산성을 향상시킬 수 있다.
③ 낙관적 로킹의 장점은 작업이 종료된 후에만 로크를 획득하기 때문에 비관적 로킹보다 로크를 가지고 있는 시간이 훨씬 짧다는 것이다.
④ 응용의 특성상 특정한 행에 많은 작업을 해야하는 트랜잭션의 경우에는 비관적 로킹을 사용 하는 것이 더 효율적이다.
55. 세 개의 릴레이션 스키마가 고객(고객번호, 이름, 주소), 계좌(계좌번호, 지점명, 잔고), 예금자(고객번호, 계좌번호, 계좌생성날짜)이고 각각의 기본키는 밑줄 친 속성이라고 하자. 계좌 릴레이션의 투플이 삭제되면 해당 예금자 릴레이션의 투플도 같이 삭제되도록 하는 방법으로 옳은 것은?
① 예금자 릴레이션을 생성할 때 FOREIGN KEY(계좌번호) REFERENCES 계좌(계좌번호) ON DELETE CASCADE 명령어를 추가한다.
② 예금자 릴레이션을 생성할 때 FOREIGN KEY(계좌번호) REFERENCES 계좌(계좌번호) IN DELETE
CASCADE 명령어를 추가한다.
③ 계좌 릴레이션을 생성할 때 FOREIGN KEY(계좌번호) REFERENCES 예금자(계좌번호) ON DELETE
CASCADE 명령어를 추가한다.
④ 계좌 릴레이션을 생성할 때 FOREIGN KEY(계좌번호) REFERENCES 예금자(계좌번호) IN DELETE CASCADE 명령어를 추가한다.
56. 다음 E-R 다이어그램을 관계 모델로 표현한 결과로 가장 적절한 것은? (단, 밑줄은 기본 키, 이탤릭체는 외래 키를 의미한다.)

① STUDENT(SNO, Name, CNO, Grade), COURSE(CNO,CName)
② STUDENT(SNO, Name), COURSE(CNO, CName,SNO, Grade)
③ STUDENT(SNO, Name), COURSE(CNO, CName), ENROL(Grade)
④ STUDENT(SNO, Name), COURSE(CNO, CName), ENROL(SNO, CNO, Grade)
57. 다음은 릴레이션 R(A, B, C, D)에 대하여 <함수적 종속성>과 <분해>를 각각 보인 것이다. 분해한 후 릴레이션 R1, R2의 정규형이 모두 BCNF 이상인 것은 어느 것인가?
① <함수적 종속성> (A, B)→D, B→C, C→D
<분해> R1(A, B), R2(B, C, D)
② <함수적 종속성> A→B, B→C, C→D
<분해> R1(A, B, C), R2(C, D)
③ <함수적 종속성> (A, B)→C, C→D, C→A
<분해> R1(A, B, C), R2(C, D)
④ <함수적 종속성> (A, B)→CD, C→A
<분해> R1(A, C), R2(B, C, D)
58. 다음과 같은 다치 종속과 함수 종속이 존재한다고 할 때 제4정규형(4NF)에 해당하는 테이블로 옳은 것은?
|
직원이름↠학위명, 직원이름↠형제이름,
직원이름↠담당상품번호, 파트키트명↠파트명, 파트키트명→가격 |
① 직원_학위(직원이름, 학위명)
② 직원_학위_형제(직원이름, 학위명, 형제이름)
③ 파트키트_파트_가격(파트키트명, 파트명, 가격)
④ 직원_상품_학위(직원이름, 담당상품번호, 학위명)
59. 인덱스에 저장되어 있는 ROWID는 오브젝트 번호, 데이터 파일 번호, 블록 번호와 같은 물리적 요소들로 구성되어 있다. <보기>는 인덱스 ROWID를 이용해 테이블 블록을 읽는 전체 메커니즘 중 일부 과정을 보여준다. 이를 순서대로 올바르게 나열한 것은?
|
<보기>
ㄱ. LRU 리스트를 스캔하면서 빈 버퍼를 찾는다. ㄴ. 디스크에서 블록을 읽어 버퍼 캐시에 적재한다. ㄷ. 해시 버켓에 연결된 해시 체인을 스캔하면서 블록 헤더를 찾는다. ㄹ. 인덱스에서 하나의 ROWID를 읽고 디스크상의 블록위치정보를 해시 함수에 적용해 해시값을 확인한다. ㅁ. Dirty 버퍼를 디스크에 기록해 빈 버퍼를 확보한다. |
① ㅁ – ㄱ - ㄴ – ㄹ - ㄷ
② ㄹ - ㄷ - ㄱ - ㅁ - ㄴ
③ ㄷ - ㄹ - ㄱ – ㄴ - ㅁ
④ ㄹ - ㄷ - ㅁ – ㄱ – ㄴ
60. 아래와 같은 STUDENT 테이블과 ENROLL 테이블에 대한 <SQL 질의문>이 수행될 때, 생성되는 결과 테이블의 카디널리티(cardinality)로 옳은 것은?
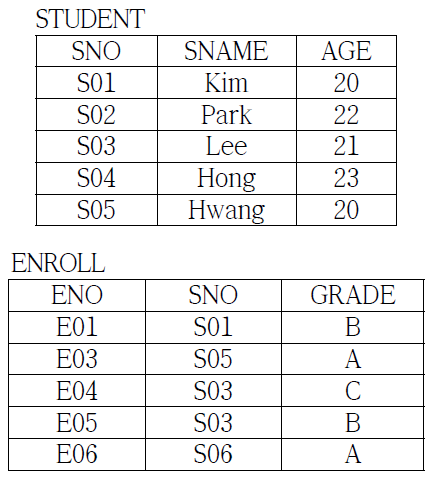
|
<SQL 질의문>
SELECT STUDENT.SNO, ENROLL.ENO, ENROLL.GRADE FROM STUDENT LEFT OUTER JOIN ENROLL ON STUDENT.SNO = ENROLL.SNO; |
① 4 ② 5 ③ 6 ④ 7
61. 다음의 세 테이블로 구성된 회사 데이터베이스에서 <보기>의 질의문이 실행되었을 때 질의 결과의 내용을 설명한 것으로 옳은 것은? (단, 테이블의 기본 키는 밑줄로 표시되어 있다.)
|
직원(직원번호, 이름, 생일, 주소, 부서번호)
부서(부서번호, 부서명, 관리자_직원번호) 부양가족(부양직원번호, 부양가족이름, 성별, 관계) |
|
<보기>
SELECT 이름 FROM 직원 WHERE EXISTS (SELECT * FROM 부양가족 WHERE 직원번호 = 부양직원번호) AND EXISTS (SELECT * FROM 부서 WHERE 직원번호 = 관리자_직원번호); |
① 적어도 한 명의 부양가족을 가진 직원의 이름을 검색하라.
② 적어도 한 명의 부양가족을 가진 관리자의 이름을 검색하라.
③ 부양가족이 있거나 관리자 역할을 하는 직원의 이름을 검색하라.
④ 관리자인 직원의 부양가족의 이름을 검색하라.
62. 검색 엔진의 평가 척도에 대한 설명으로 적절하지 않은 것은?
① 리콜(recall)은 데이터베이스에 있는 전체 관련 문서 중에서 실제 검색된 관련 문서의 비율이다.
② 주어진 질의에 대한 관련 문서가 10개라고 할때, 5개의 문서를 검색했는데 관련된 문서가 3개라면 정확도(precision)는 60%이고 리콜(recall)은 30%이다.
③ 랭킹(ranking)이 주어된 검색 결과에서 평균 정확도(average precision)는 검색 결과 중 관련이 있는 문서들의 정확도 값의 평균을 구한 것이다.
④ F-스코어(F-score)는 정확도(precision)와 리콜(recall)의 조화 평균으로 두 값 중 더 큰 쪽으로 가까워지는 경향이 있다.
63. 다음의 데이터베이스에서 (가)는 VIEW를 생성한 것이고 (나)는 생성된 VIEW에 대한 검색 명령어이다. 이 검색 명령어가 실제 실행되기 위해서 질의 변경(query modification)되는 SQL 명령어로 옳은 것은? (단, Students, Enrolled 릴레이션 각각의 기본 키는 밑줄 친 속성이다.)
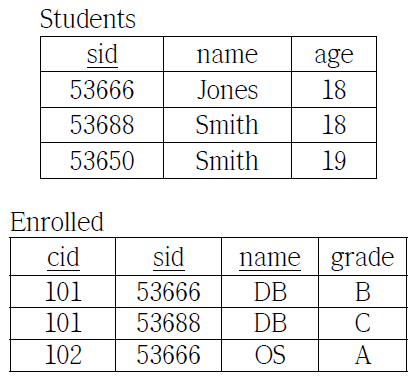
|
(가) CREATE VIEW BStudents (name, sid, cid)
AS SELECT S.name, S.sid, E.cid FROM Students S, Enrolled E WHERE S.sid=E.sid AND E.grade=‘B’; (나) SELECT name FROM BStudents WHERE cid=‘101’; |
① SELECT S.name
FROM Students S, Enrolled E
WHERE E.grade=‘B’ AND E.cid=‘101’;
② SELECT E.name
FROM Students S, Enrolled E
WHERE E.grade=‘B’ AND E.cid=‘101’;
③ SELECT S.name
FROM Students S, Enrolled E
WHERE S.sid=E.sid AN D E.grade=‘B’
AN D E.cid=‘101’;
④ SELECT E.name
FROM Students S, Enrolled E
WHERE S.sid=E.sid AN D E.grade=‘B’
AN D E.cid=‘101’;
64. 다음은 자동차 소유주(OWNER)와 차량(VEHICLE)의 관계를 EER 모델로 표현한 것이다. 이 EER 모델에서 사람(PERSON), 은행(BANK), 회사(COMPANY) 개체가 자동차 소유주가 될 수 있음을 표현하기 위해 사용된 모델링 개념으로 옳은 것은?
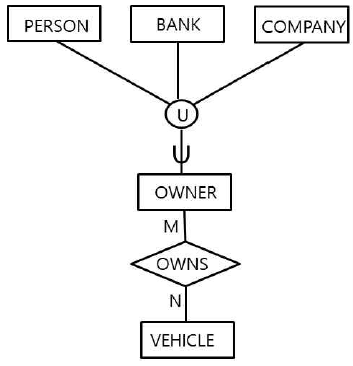
① 세분화(specialization) ② 일반화(generalization)
③ 범주(category) ④ 집단화(aggregation)
65. <보기>는 트리거(trigger)와 저장 프로시저(stored procedure)의 특성을 설명한 것이다. 저장 프로시저에 해당하는 특성만을 모아놓은 것으로 가장 적절한 것은?
|
<보기>
ㄱ. 입력 인자를 받을 수 있고 결과를 돌려줄 수 있다. ㄴ. 테이블이나 뷰에 할당된다. ㄷ. INSERT, DELETE, UPDATE 명령 실행시 DBMS에 의하여 수행된다. ㄹ. 데이터베이스에 저장되어 필요시 컴파일되며 데이터베이스에 부속된다. |
① ㄱ, ㄴ ② ㄴ, ㄷ
③ ㄱ, ㄹ ④ ㄷ, ㄹ
66. 정보검색(information retrieval)을 위한 텍스트 전처리 과정 중 스테밍(stemming) 단계의 결과로 옳은 것은?
① 중요한 개념들의 리스트와 각 개념을 기술하는주요 단어들로 구성된다.
② 매우 자주 사용되는 단어들이나 문장 의미에는 거의 기여하지 못한다.
③ 원래 단어의 접두사나 접미사를 잘라낸 후에 얻는 단어이다.
④ 문서 컬렉션에서 80% 이상 등장하는 단어들이다.
67. 질의 최적화에서는 주어진 식을 다른 식으로 변경하기 위해 동등 규칙(equivalence rule, ≡)을 사용한다. 관계 대수(relational algebra)에 대한 다음 규칙 중에서 올바른 동등 규칙을 모두 나열한 것은?
 |
① 가, 다
② 가, 나, 다
③ 나, 다, 라
④ 가, 나, 다, 라
68. 다음에서 ⓐ는 EMPLOYEE의 스키마와 속성을 설명하고, 질의 ⓑ는 “5번 부서에 근무하는 모든 사원보다 급여가 많은 사원을 검색하라”를, 질의 ⓒ는 “5번 부서에 근무하는 어느 한 사원보다 급여가 많은 사원을 검색하라”를 각각 나타낸다. 다음 질의에서 ㉮와 ㉯에 들어갈 내용으로 가장 올바른 것은?
|
ⓐ
|
EMPLOYEE
 |
|
ⓑ
|
SELECT NAME
FROM EMPLOYEE WHERE SALARY ㉮ ( SELECT SALARY FROM EMPLYEE WHERE DNO=5); |
|
ⓒ
|
SELECT NAME
FROM EMPLOYEE WHERE SALARY ㉯ ( SELECT SALARY FROM EMPLYEE WHERE DNO=5); |
㉮ ㉯
① > EVERY > ONE
② > ALL > ONE
③ > EVERY > ANY
④ > ALL > ANY
69. 부서(DEPARTMENT) 개체와 직원(EMPLOYEE) 개체 사이에 1:N 소속 관계가 존재하고, 부서는 이 관계에 부분 참여하고, 직원은 이 관계에 전체 참여한다고 하자. 즉, 부서에는 최소 0명, 최대 N명의 직원이 소속되고, 직원은 최소 1개, 최대 1개의 부서에 소속이 된다. 이러한 상황을 반영하여 부서(부서명, 예산코드), 직원(직원번호, 이름, 이메일, 입사일, 부서명) 테이블을 생성하려 한다고 하자. 최소 카디널리티(cardinality)를 준수하도록 하기 위한 조치로 가장 적절한 것은? (여기서, 밑줄은 기본 키,이탤릭체는 외래 키를 의미한다.)
① 전형적인 1:N 관계로 특별히 문제될 것이 없는 상황이다.
② 직원 테이블의 부서명 속성을 ‘NOT NULL’인 외래 키로 정의한다.
③ 부서 테이블에 대한 투플 입력시 직원 테이블에 투플을 삽입하는 트리거(trigger)를 작성한다.
④ 복잡한 트리거의 조합을 필요로 하고 트리거는 서로에게 로크를 걸 수 있다.
70. 다음은 릴레이션 R1(id, age), R2(id, age)와 <SQL 질의문>이다. <SQL 질의문>의 실행결과로 가장 적 절한 것은?
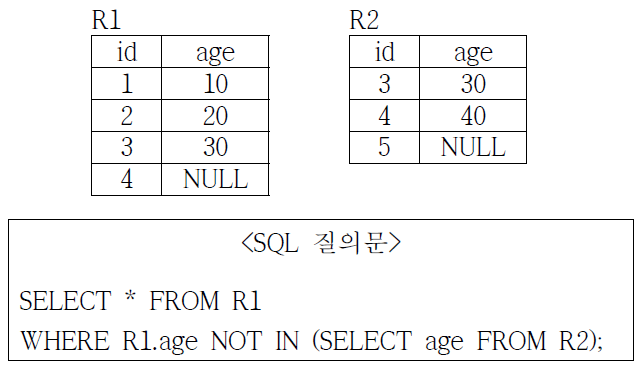

71. 다음 확장성 해시(extendible hash) 파일에서 전역 깊이(global depth)를 (가)로 나타내고 지역 깊이(local depth)를 (나)로 나타낸다고 할 때, 모조키가 000010인 레코드가 삽입된 후, 변경된 확장성 해시 파일에 대해 전역 깊이(가)와 모든 버킷의 지역 깊이(나)의 합을 각각 옳게 나열한 것은?
(단, 한 버킷에는 최대 4개의 레코드가 포함된다.)
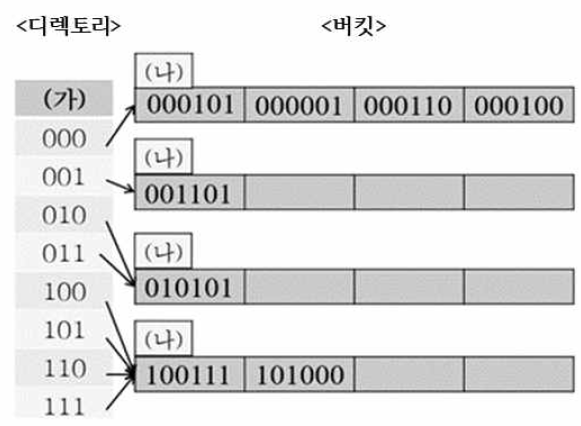
① 전역 깊이 3, 지역 깊이의 합 11
② 전역 깊이 4, 지역 깊이의 합 11
③ 전역 깊이 3, 지역 깊이의 합 14
④ 전역 깊이 4, 지역 깊이의 합 14
72. 다음은 Apache Spark에서 사용하는 데이터 구조에 대한 설명이다. 다음 설명에서 ㉮에 들어갈 용어로 가장 올바른 것은?
|
관계형 데이터베이스가 데이터 표현을 위한 추상화로 릴레이션을 사용하는 것처럼 Apache Spark은 ㉮라 불리는 데이터 표현 방식을 사용한다. Spark 에서 연산자는 하나 이상의 ㉮를 입력으로 받아 출력으로 ㉮를 반환하는 방식으로 계산을 수행한다.
|
① HDFS(Hadoop Distributed File System)
② HDFS(Hadoop Duplicated File System)
③ RDD(Resilient Distributed Dataset)
④ RDD(Reproducible Duplicated Dataset)
73. 다음 데이터가 순서대로 삽입되어 만들어진 차수가 3인 B-트리에 대한 설명으로 옳지 않은 것은?
|
17, 20, 5, 15, 7, 18, 16, 19
|
① 루트 노드의 키 값은 16이다.
② 리프 노드의 개수는 4개이다.
③ 전체 노드의 개수는 7개이다.
④ 루트 노드의 레벨이 1이라고 할 때, 트리의 높이는 3이다.
74. WAL(Write-Ahead Logging) 기법은 두 가지 로그 엔트리를 사용한다. 먼저 항목의 AFIM(After Image)을 기록하는데 이는 트랜잭션의 (가)에 대비하기 위함이며, 항목의 BFIM(Before Image)을 기록하는데 이는 트랜잭션의 (나)에 대비하기 위함이다. 이때, (가)와 (나)에 들어갈 용어로 가장 올바른 것은?
① (가) VOLATILE (나) PERSISTENT
② (가) PERSISTENT (나) VOLATILE
③ (가) REDO (나) UNDO
④ (가) UNDO (나) REDO
75. 다음 조건에서 k-Means 군집화를 수행한다고 할때, 유사도(점과 점 사이의 거리) 계산 횟수로 가장 가까운 것은?
|
① 125 ② 1025 ③ 1495 ④ 2375
정답)
|
51
|
52
|
53
|
54
|
55
|
|
①
|
②
|
④
|
①
|
①
|
|
56
|
57
|
58
|
59
|
60
|
|
④
|
④
|
①
|
②
|
③
|
|
61
|
62
|
63
|
64
|
65
|
|
②
|
④
|
③
|
③
|
③
|
|
66
|
67
|
68
|
69
|
70
|
|
③
|
④
|
④
|
②
|
③
|
|
71
|
72
|
73
|
74
|
75
|
|
④
|
③
|
①
|
③
|
④
|
공감과 댓글은 아이티신비에게 큰 힘이 됩니다.
블로그 글이 유용하다면 블로그를 구독해주세요.♥
'정보시스템감리 기출문제 > 데이터베이스' 카테고리의 다른 글
| (제 14회) 데이터베이스 / (51)~(75) (2) | 2024.01.12 |
|---|---|
| (제 15회) 데이터베이스 / (51)~(75) (2) | 2024.01.11 |
| (제 16회) 데이터베이스 / (51)~(75) (0) | 2024.01.10 |
| (제 17회) 데이터베이스 / (51)~(75) (1) | 2024.01.09 |
| (제 18회) 데이터베이스 / (51)~(75) (1) | 2024.01.08 |